Сетевые операционные системы
Разделение памяти
Разделение играет важную роль в Mach. Для разделения объектов нитями одного процесса никаких специальных механизмов не требуется: все они автоматически видят одно и то же адресное пространство. Если одна из них имеет доступ к части данных, то и все его имеют. Более интересной является возможность разделять двумя или более процессами одни и те же объекты памяти, или же просто разделять страницы памяти для этой цели. Иногда разделение полезно в системах с одним процессором. Например, в классической задаче производитель-потребитель может быть желательным реализовать производителя и потребителя разными процессами, но иметь общий буфер, в который производитель мог бы писать, а потребитель - брать из него данные.
В многопроцессорных системах разделение объектов между процессами часто более важно, чем в однопроцессорных. Во многих случаях задача решается за счет работы взаимодействующих процессов, работающих параллельно на разных процессорах (в отличие от разделения во времени одного процессора). Этим процессам может понадобиться непрерывный доступ к буферам, таблицам или другим структурам данных, для того, чтобы выполнить свою работу. Существенно, чтобы ОС позволяла такой вид разделения. Ранние версии UNIX'а не предоставляли такой возможности, хотя потом она была добавлена.
Рассмотрим, например, систему, которая анализирует оцифрованные спутниковые изображения Земли в реальном масштабе времени, в том темпе, в каком они передаются со спутника. Такой анализ требует больших затрат времени, и одно и то же изображение может проверяться на возможность его использования в предсказании погоды, урожая или отслеживании загрязнения среды. Каждое полученное изображение сохраняется как файл.
Для проведения такого анализа можно использовать мультипроцессор. Так как метеорологические, сельскохозяйственные и экологические программы очень отличаются друг от друга и разрабатываются различными специалистами, то нет причин делать их нитями одного процесса. Вместо этого каждая программа является отдельным процессом, который отображает текущий снимок в свое адресное пространство, как показано на рисунке 6.6.
Заметим, что файл, содержащий снимок, может быть отображен в различные виртуальные адреса в каждом процессе. Хотя каждая страница только один раз присутствует в памяти, она может оказаться в картах страниц различных процессов в различных местах. С помощью такого способа все три процесса могут работать над одним и тем же файлом в одно и то же время.
Другой важной областью разделяемости является создание процессов. Как и в UNIX'е, в Mach основным способом создания нового процесса является копирование существующего процесса. В UNIX'е копия всегда является двойником процесса, выполнившего системный вызов FORK в то время как в Mach потомок может быть двойником другого процесса (прототипа).
Одним из способов создания процесса-потомка состоит в копировании всех необходимых страниц и отображения копий в адресное пространство потомка. Хотя этот способ и работает, но он необоснованно дорог. Коды программы обычно используются в режиме только-для-чтения, так что их нельзя изменять, часть данных также может использоваться в этом режиме. Страницы с режимом только-для-чтения нет необходимости копировать, так как отображение их в адресные пространства обоих процессов выполнит необходимую работу. Страницы, в которые можно писать, не всегда могут разделяться, так как семантика создания процесса (по крайней мере в UNIX) говорит, что хотя в момент создания родительский процесс и процесс-потомок идентичны, последовательные изменения в любом из них невидимы в другом адресном пространстве.
Кроме этого, некоторые области (например, определенные отображенные файлы) могут не понадобиться процессу-потомку. Зачем связываться с массой забот, связанных с отображением, если эти области просто не нужны?
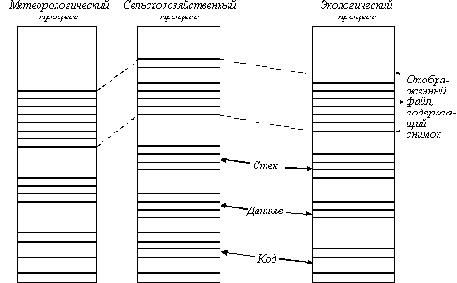
Рис. 6.6. Три процесса, разделяющие отображенный файл
Для обеспечения гибкости Mach позволяет процессу назначить атрибут наследования
